信安之路入坑指南
疫情下的高考已结束,又快到填志愿的时候了,又有不少知青要加入信安这个圈子。为了响应组织号召,撰写此文作为信安行业的入坑指南,希望能对刚入圈的同学有所帮助。
如何入门学习
1、明确目标,并以目标为导向,用以致学
刚开始的时候,相信很多人会先去搜索信息安全要学什么课程,可能有人会告诉你要先C,再学数据结构和算法,学数据结构和算法前又要学离散数学,总之会有无穷无尽的东西在等着你,导致最后自己都不知道该学啥了……
其实学习什么课程都只是手段而已,但你学习这些课程的目标是什么需要先明确,比如想去国内个的漏洞奖励平台刷web或软件漏洞拿奖金,或者报个CVE漏洞,开源个安全项目等等,这样目标和动力就都有了。
2、细化目标制定具体的学习内容
假设你的目标是挖腾讯PC软件漏洞赚奖金吧,那腾讯PC软件有啥,电脑管家、腾讯视频、QQ、QQ影音等等,先选个门槛低点的QQ影音吧,目标就细化成挖掘音视频文件解析软件的漏洞。
挖掘文件解析漏洞的技术就涉及 代码审计、Fuzzing、逆向等等,再细化下目标,挑Fuzzing吧。
入门Fuzzing涉及哪些系统性的技术内容呢?可以拿国外知名大会的培训课程为例,比如BlackHat、CanSecWest等等,这里以CanSecWest上的“Advanced Fuzzing and Crash Analysis”培训课程为例:
https://cansecwest.com/dojos/2019/vulndisco.html
4天的培训课程计划已经给出了循序渐进的学习内容,你只需要多利用搜索引擎去查找相关的书籍、论文、工具进行学习和实践。
比如课程给出的前置条件:
Students should be prepared to tackle challenging and diverse subject matter and be comfortable writing functions in in C/C++ and python to complete exercises involving completing plugins for the discussed platforms. Attendees should have basic experience with debugging native x86/x64 memory corruption vulnerabilities on Linux or Windows.
涉及C/C++、Python和汇编,这里就需要先去找相应语言的经典书籍先入个门,至少保证先看得懂代码。
再看第一天的课程目录,用相关标题去搜索就可以得到相关的知识点,比如AFL、libFuzzer、Corpus generation等等,遇到不懂的就是一个知识点,自己设法去弄懂并实践它就是学习的过程:

整个示例过程总结起来就是:
挖腾讯漏洞赚钱 =》PC软件 =》QQ影音 =》文件Fuzzing =》培训课程目录 =》搜索相关书籍、论文、工具进行学习
其它目标的学习内容制定类似,包括web渗透、内核攻击等等。
3、无限循环:学习=》应用=》反馈=》学习
完成第2步的学习之后,就去实践(示例:挖QQ影音的漏洞,或者其它已公开的漏洞的挖掘验证),看能否挖到0day或1day,若不能就针对公开漏洞的信息继续改进优化,再验证效果,以此不断循环,直至相信这是体力问题,也不是能力问题。
这里以二进制漏洞学习为例,但其它领域web、IoT方向都均适用。学习过程遇到迷茫,很多时候只是不知道目标和手段(学习计划等)之间的关联性而已,设法找到它,并细化到可执行的内容,再设置一些里程碑目标(比如重现历史漏洞的挖掘过程)来增加自信心,最后就是持之以恒下去。
关于CTF
在学校时,有机会就多去打打CTF,提高实战能力,国内不少课程内容都比较落后,现在也有一些高校会直接采用工业界出版的一些书籍作为教材,也是一种进步。
一本书的出版经常代表着其内容已经过时,除了一些计算机基础书籍,比如C/C++、编译原理、系统原理等等这些,即使再过10年也不会过时。其它很多技术会随时时代变迁,技术日新月异,而CTF题目往往会跟着技术热潮来变更,在学习基础的同时,又能帮助跟上技术的更新变化节奏。
学习工具推荐
印象笔记、Mendeley、Inoreader是我最想推荐的三款工具,均有跨平台客户端,以及浏览器插件,数据在多平台同步,搭配使用非常方便。
关于Mendeley和Inoreader的使用,我也曾写过文章推荐,详见《谈谈追踪前沿学术研究的技巧》和《RSS-优秀的个人情报来源》
平时我Inoreader订阅RSS,用印象笔记来收藏文章,用Mendeley追踪学术论文,并在上面作笔记,方便未来查阅和复习。另外,Mendeley还有个功能,就是会根据你所收藏的论文,去推荐更多相关技术的论文,比如参考文献中的内容。比如关注Linux Kernel Fuzzing,那么它会推荐更多的内核Fuzzing论文给你,如果有公开的PDF下载,还可以直接通过它索引下载,这种学术论文的追踪并不是印象笔记能比的。个人主要是用印象笔记来收藏一些非学术论文的文章,还有一些工业界安全会议的ppt等等。
对推荐书单的补充说明
之前笔者曾发过”信息安全从业者书单推荐”(https://github.com/riusksk/secbook),相信很多圈内人看过,期间也很多人提问过,这里整理补充说明下。
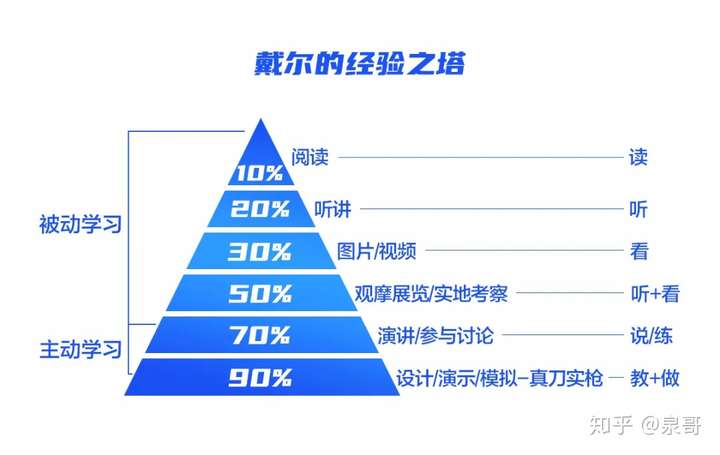
- 配合书籍,注重实战:列举那么多书并不是想让大家从头翻到尾看完,而主要是向大家推荐一些我曾经看过并觉得较好的书而已,大家自己根据自己需要选择即可。同时,理论归理论,很多东西需要配合实战,光看书也没用,依然建议大家试试”用以致学”的方法。
- 书单并非网上收集列举的:由于书单较多,有不少人质疑只是把网上有的书随便收集罗列下而已。之前在github回应过,这里再说明下。书单均是个人看过或者业界认可的经典书籍(部分书籍没全看完,但不妨碍对书籍质量的判断),跟网上罗列的安全书单不同,并非把网店上的各安全书籍都罗列上的。如果你有何好书推荐可在
Github Issues上提交合并,待我看过之后,如果觉得可以就会在此处更新,会在Github上不定期更新书单。 - 关于阅读时间的问题:多数人一看到书单,就会问这些得多久才能读完?我觉得没必要纠结于此,有空有兴趣就挑本书看下即可,读书没必要把它当作一种负担,保持细水长流的方式,持续学习就好了。如果真的说时间的话,我从06开始学习安全,到今天差不多14年,14年读完那些书,我觉得问题也不大,但关键在于自己掌握了多少。我建议抛开时间、数量的考量,遵循自我内心的喜好,保持学习即可。
- 书单仅代表个人喜好:不同人对同一本书通常会有不同的评价,这里仅代表个人喜好,你可以有不同的看法。比如有些人曾推荐过《逆向工程核心原理》,但我觉得它内容过旧,且没有《加密与解密》写得好,所以我一直没入书单推荐。但你觉得此书对你有帮助,那就保持你的这份喜好,不必执着于书单本身。